
New York / March 24, 2017
MLConf NYC was held in NYC for the 4th time and I was one of the lucky attendees for the 1st time this year. Thanks everyone who made MLConf possible and thank you Women in Machine Learning and Data Science for giving me the opportunity to participate.
You were mostly surrounded by the celebrities of data science. It was a pretty good atmosphere to discuss recent research and applications of Machine Learning methodologies, practices and how they’re presently applied in industry.

There were 17 talks in total from 9 AM to 5:30 PM at 230 5th Ave (not only the atmosphere, talks and networking opportunities; the view was pretty good too).
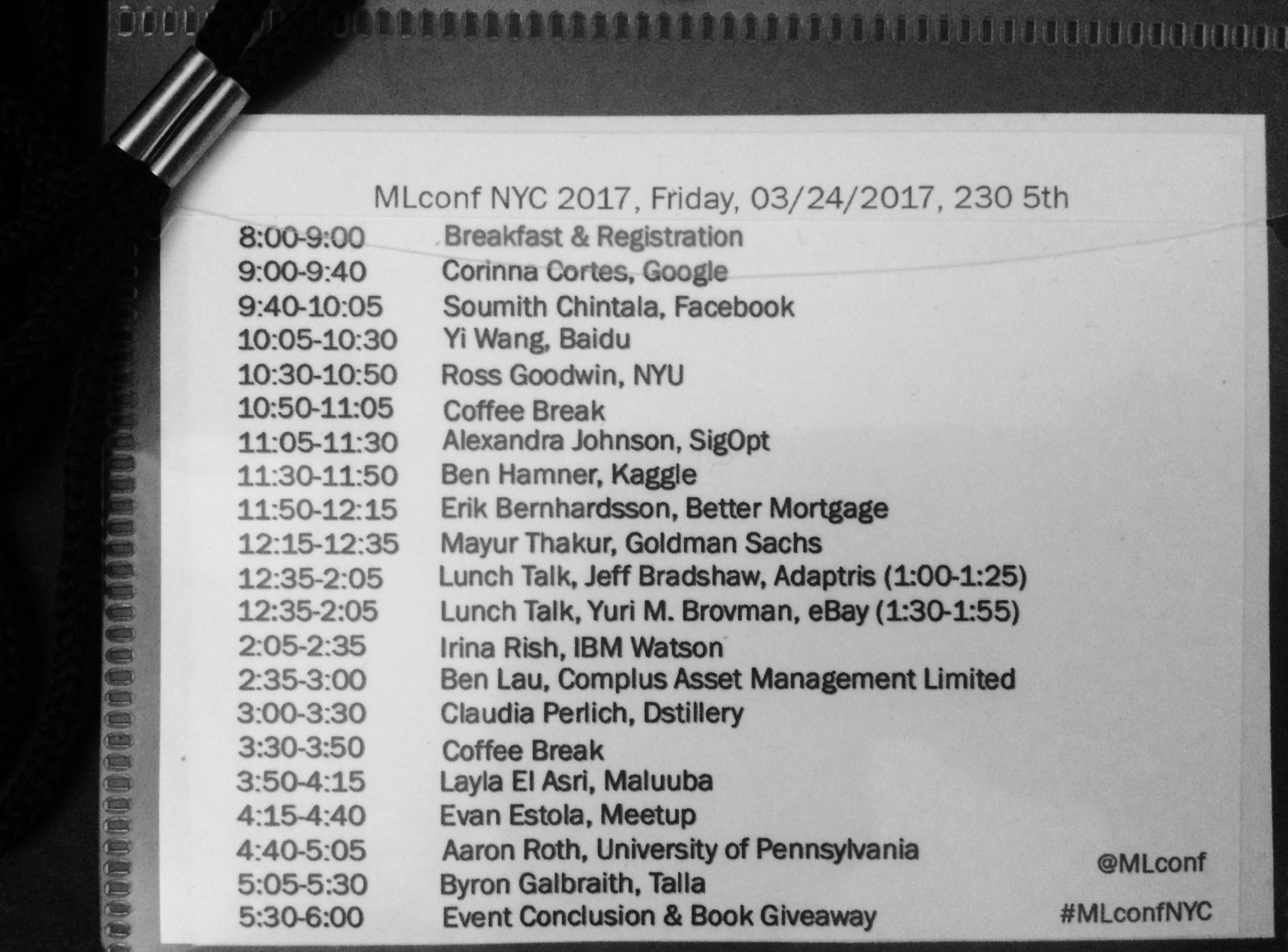
1 - The first talk was from Corinna Cortes, Head of Research at Google. Her research work is well-known in particular for her contributions to the theoretical foundations of support vector machines (SVMs). Her talk (Harnessing the Power of Neural Networks) was a nice summary of neural network limitations and challenges; it was mainly divided into 3 topics:
- How do we standardize the output?
- How do we speed up the inference?
- How do we automatically find a good network architecture?
2 - Second talk was from Soumith Chintala, Artificial Intelligence Research Engineer at Facebook. He talked about today and tomorrow of research and tools of AI.
3 - Third talk - Fault-Tolerable Deep Learning on General-Purpose Clusters - was from Yi Wang, Tech Lead of AI Platform at Baidu. He started with a business case and talked about the integration of PaddlePaddle (PArallel Distributed Deep Learning which is originally developed by Baidu scientists and engineers for the purpose of applying deep learning to many products at Baidu.) and Kubernetes to provide an open source fault-tolerable large-scale deep learning platform.
4 - A creative technologist Ross Goodwin was the fourth speaker. I can say it was one of my favorite talk as a person who love to see art, science and creativity together. He combines deep learning, sensors and poetics to create fascinating narrative art. If you want to watch a sci-fi film written by an LSTM, check this out. For more info about Ross, you can check his website.
5- After the first coffee break the fifth talk was from Alexandra Johnson, Software Engineer at SigOpt. She talked about common problems in hyperparameter optimization:
- Trusting the Defaults
- Using the Wrong Metric
- Overfitting
- Too Few Hyperparameters
- Hand-tuning
- Grid Search
- Random Search
For more information, here is a post about her talk and slides.
6 - Sixth talk was given by Ben Hamner, CTO of Kaggle: “The Future of Kaggle: Where We Came From and Where We’re Going
I love Kaggle - It was nice to hear from him about new developments and see Kaggle as a platform that supports reproducible, collaborative data science work.
7 - Next speaker was Erik Bernhardsson, CTO of Better Mortgage. Before Better, he spent 5 years at Spotify working on music recommendations. In his talk “Nearest Neighbor Methods And Vector Models”, he talked about the pros and cons about vector models: “Vector models are being used in a lot of different fields: natural language processing, recommender systems, computer vision, and other things. They are fast and convenient and are often state of the art in terms of accuracy. One of the challenges with vector models is that as the number of dimensions increase, finding similar items gets challenging.” and library he developed, “Annoy” that uses a forest of random tree to do fast and approximate nearest neighbor queries in high dimensional spaces.
8 - Eighth talk was from Mayur Thakur, Managing Director, Goldman Sachs. He talked about their experience building a Hadoop-based platform for surveillance.
9 - During lunch, we had 2 talks: Jeff Bradshaw, Founder of Adaptris talked about Precision agriculture – Predicting outcomes for farmers using machine learning to help feed the world.
10 - The second talk during lunch, Innovations in Recommender Systems for a Semi-structured Marketplace, was from Yuri M. Brovman, Data Scientist at eBay NYC. eBay has over 1 billion live items on the site at any given time. The lack of structured information about listings as well as variable inventory makes traditional collaborative filtering algorithms difficult to use in eBay’s large semi-structured marketplace. He discussed approaches to overcome these challenges using machine learning and deep learning (both text and image based models). (See the related paper)
11 - Irina Rish, Researcher at the AI Foundations- Department of the IBM T.J. Watson Research Center was the next one and her talk was Learning About the Brain and Brain-Inspired Learning: She talked about mental state recognition to improve mental function such as:
- Computational Psychiatry: data analytic approach to diagnosis based on objective measurements with focus on schizophrenia, addiction, alzheimer’s, huntington’s, parkinson’s
- Health and Productivity: mental-state-sensitive software monitoring cognitive load, focus/attention; monitoring stress/anxiety
- Safety: detecting changes in driver’s alertness level to prevent accidents
- Detecting emotional and cognitive changes to predict responses to different types of input such as music, video, news, ads etc (See: EEGLearn )
Besides the AI to Brain direction, she also discussed about “Brain to AI”, namely, borrowing ideas from neuroscience to improve machine learning.
12 - Twelfth talk was from Ben Lau, Quantitative Researcher at Complus Asset Management Limited. He talked about Deep Reinforcement Learning and how to apply it to train a self driving car under an open source racing car simulator called TORCS.
Link for more details and python code that demonstrates Deep Deterministic Policy Gradient (DDPG) with Keras.
13 - Next one was Claudia Perlich, Chief Scientist at Dstillery with her talk Predictability and other Predicaments. She talked about model bias, how predictable is a predictive modeling task. For many applications the relevant outcome is observed for very different reasons. In this case the model will automatically gravitate to the one that is easiest to predict at the expense of the others. She gave a couple applications where this happens such as clicks on ads being performed ‘intentionally’ vs. ‘accidentally’. In conclusion, the combination of different and highly informative features can have significantly negative impact on the usefulness of predictive modeling.
14 - After the 2nd coffee break, Layla El Asri, Research Scientist at Maluuba was on stage. Her talk was Teaching AI To Make Decisions and Communicate. She talked about learning to learn, learning to perceive and learning to communicate.
15 - Fifteenth talk was from Evan Estola, Lead Machine Learning Engineer at Meetup. In his talk, Machine Learning Heresy and the Church of Optimality, he focused on the ethics of machine learning applications. What does it mean for an algorithm to be fair? How about using sensitive features like age, race and gender? By restricting or removing certain features aren’t you sacrificing performance? Isn’t it actually adding bias if you decide which features to put in or not? If the data shows that there is a relationship between X and Y, isn’t that your ground truth?
16 - Aaron Roth, Associate Professor at University of Pennsylvania and co-author of the book “The Algorithmic Foundations of Differential Privacy.” In his talk, “Differential Privacy and Machine Learning”, he gave an introduction to differential privacy and the relationship with machine learning.
17 - The last talk, “Bayesian Bandits” was given by Byron Galbraith, Chief Data Scientist at Talla. What color should that button be to convert more sales? What ad will most likely get clicked on? What movie recommendations should be displayed to keep subscribers engaged? What should we have for lunch? He described the Bayesian Bandit solution to these kind of iterated decision problems, how it adaptively learns to minimize regret, how additional contextual information can be incorporated, and how it compares to the more traditional A/B testing solution.
Here is the playlist of the talks and link to see speaker resources.
Again, it was so nice to be there. Thanks everyone who made MLConf possible and all the sponsors who supported the organization.